
Песочница →
PowerShell+Hyper-V
Не могу уже через gui...
Примерно так начинался мой разговор с другом которому в течение короткого промежутка времени пришлось несколько раз подряд экспортировать виртуальные машины из Hyper-V. Обычно для этого используется Hyper-V Manager (HVM), который устанавливается вместе с ролью Hyper-V под Windows Server 2008 R2. Я должен признаться что интерфейс этой программы не вызывает у меня каких-либо негативных эмоций. Среди всех программ для управления, которые Microsoft поставляет к Server эта мне кажется наиболее удобной и понятной (сравниваю например с IIS Manager, который вызывает недоумение у новых пользователей и бурное негодование у тех кто использовал IIS 6 в 2003 Server). Однако если нужно экспортировать или импортировать виртуальную машину в количестве N-штук в промежуток t-времени то используя Hyper-V Manager можно сломать кнопку у мыши и жутко возненавидеть Hyper-V. Тут на помощь и приходит PowerShell.
03.06.2011 21:40+0400
Ни о чём →
Будет ли вам интересна статья про постиндустриальное общество?
У меня сейчас в черновиках лежит недописанная статья «Постиндустриальное общество: ценности, семья, мораль и право», по мотивам предыдущих топиков про порнографию и мозг.
Лежит давно, пишется с трудом. Поэтому хочу заранее спросить, будет ли эта статья здесь востребована.
Смысл следующий: я пытаюсь показать, что специфические социальные особенности постиндустриального общества — либерализация морали (в т.ч. сексуальной), либерализация права (легализация наркотиков, проституции, порнографии), деградация института брака, снижение рождаемости — объяснимы со вполне рациональных позиций и вполне логичны.
Если интересно, пишите в комменты. Если неинтересно, тоже пишите в комменты.
Кстати, сразу анонсирую следующую статью — про государство, общество и национализм. Можно и за неё сразу голосовать :).
Лежит давно, пишется с трудом. Поэтому хочу заранее спросить, будет ли эта статья здесь востребована.
Смысл следующий: я пытаюсь показать, что специфические социальные особенности постиндустриального общества — либерализация морали (в т.ч. сексуальной), либерализация права (легализация наркотиков, проституции, порнографии), деградация института брака, снижение рождаемости — объяснимы со вполне рациональных позиций и вполне логичны.
Если интересно, пишите в комменты. Если неинтересно, тоже пишите в комменты.
Кстати, сразу анонсирую следующую статью — про государство, общество и национализм. Можно и за неё сразу голосовать :).
03.06.2011 15:00+0400
finance →
Как купить акции IT-компаний на зарубежных биржах? (часть 2)
 В первой части этой статьи мы рассмотрели теоретические основы торговли акциями на американских фондовых рынках (NASDAQ, NYSE, AMEX). Ознакомились с основными понятиями, определениями и принципами. Если во второй части что-то будет непонятно, то, возможно, вы не слишком внимательно ознакомились с первой частью. Всегда можете вернуться туда и что-то уточнить.
В первой части этой статьи мы рассмотрели теоретические основы торговли акциями на американских фондовых рынках (NASDAQ, NYSE, AMEX). Ознакомились с основными понятиями, определениями и принципами. Если во второй части что-то будет непонятно, то, возможно, вы не слишком внимательно ознакомились с первой частью. Всегда можете вернуться туда и что-то уточнить.Во второй части я хотел сформулировать и изложить пошаговое практическое руководство, т.е. некий HowTo о том, как купить какие-то конкретные акции на бирже NASDAQ или NYSE. Допустим, вы захотели купить акции какой-то конкретной компании, например, Google, Apple, Microsoft, Yandex, Intel или Tesla Motors с целью инвестиций (в расчёте на рост стоимости этих акций в будущем).
Что для этого нужно, и с чего вообще начать?
03.06.2011 03:11+0400
Энергия →
Презентация второй части фильма Джона Бедини «Энергия из вакуума»
Здравствуйте уважаемые хабропользователи!

Я хотел бы пригласить вас на эксклюзивный просмотр второй части фильма Джона Бедини — «Энергия из вакуума». Он будет показан сегодня в 20.00 на сайте www.zaryad.com, потому всем, кому интересна тема альтернативной энергии с научной и исследовательский стороны, я рекомендую зайти в это время на сайт и посмотреть данный фильм. Вы также сможете скачать его позже, он будет выложен на ftp и torrent. Те кто пока ещё не интересуется альтернативной энергией и данным фильмом, прошу под кат, где я более подробно объясню что это, и как это может нам помочь.
Я хотел бы пригласить вас на эксклюзивный просмотр второй части фильма Джона Бедини — «Энергия из вакуума». Он будет показан сегодня в 20.00 на сайте www.zaryad.com, потому всем, кому интересна тема альтернативной энергии с научной и исследовательский стороны, я рекомендую зайти в это время на сайт и посмотреть данный фильм. Вы также сможете скачать его позже, он будет выложен на ftp и torrent. Те кто пока ещё не интересуется альтернативной энергией и данным фильмом, прошу под кат, где я более подробно объясню что это, и как это может нам помочь.
02.06.2011 19:31+0400
Бизнес →
Сам себе пиарщик. Писатели и спикеры

Пиар и маркетинг – это всегда последние строчки в бюджете малого бизнеса. Что тут говорить, если даже большие компании в трудные времена первым от финансирования отрезают отдел маркетинга. Бывает, что его отрезают не только от финансирования. И, если у большой компании есть жировая прослойка в виде сильного бренда и его приверженцев, которые будут расхваливать его какое-то время без поддержки Центра, то у малого бизнеса таких преимуществ нет. Стартап не может позволить себе замолкать ни на секунду. Тут как в сказке про дудочку и кувшинчик: как только дудочка замолкает, ягодки прячутся.
Даже если у компании совсем нет денег, инструменты условно-бесплатного пиара есть всегда. Я называю их бесплатными условно, потому что на пиар всё равно придётся потратить какое-то время. Первое на что стоит потратить время – выявление талантливых и способных членов команды.
02.06.2011 13:58+0400
Ни о чём →
Из США в Россию за неделю… Почта России может!
Очень много негатива на почту, но всетаки негатив он выплескивается всегда, а вот положительные отзывы никто не публикует, считая это в порядке вещей. Под катом скриншот трекинга моей посылки. Надеюсь это скоро войдет в обычную практику.
02.06.2011 11:16+0400
Язолъ →
Интерфейс банкоматов Сбербанка 4 месяца спустя
Все наверное помнят топик, где обсуждось убожество интерфейса банкоматов Сбербанка.
Официальный представитель Сбербанка sberbank сначала пенял на то, что конструктивной критики почти нет, только и делаем, что говном поливаем, на что были сформулированы простые запросы:
1. Кнопка «Баланс» должна называться «Баланс» и находиться на первой странице.
2. Кнопка «Выдача наличных» должна называться «Выдача наличных» и находиться на первой странице.
sberbank ответил:
… конструктивные жалобы — это подарок для нас. Из похвального отзыва не вынести столько полезного и не улучшить качества сервиса. Уже на ближайшей встрече в субботу будем обсуждать с IT-департаментом полученные жалобы с хабра.
Я очень благодарна всем, кто помогает нам стать лучше. Спасибо!
Прошло 4 месяца.
Ничего не изменилось! Они добавили пункт «Заполнить заявление на получение кредитной карты» в некоторые отделы меню. Спасибо!
Я сегодня начну процесс перевода стипендии и зарплаты в университете с карточки сбербанка в другой, адекватный банк. Я отдаю себе отчёт в том, как меня затрахают тётушки в бухгалтерии. Но мне надоел этот хамский сервис, это наплевательское отношение к своей работе, вечно неработающие банкоматы и отключение процессинговых центров в будний день. Я голосую рублём.
forgotten был прав, на Сбербанке с его текущим руководством можно ставить крест.
upd: кто-то целенаправленно меня сливает, скоро я не смогу ответить на комментарии, извините.
Официальный представитель Сбербанка sberbank сначала пенял на то, что конструктивной критики почти нет, только и делаем, что говном поливаем, на что были сформулированы простые запросы:
1. Кнопка «Баланс» должна называться «Баланс» и находиться на первой странице.
2. Кнопка «Выдача наличных» должна называться «Выдача наличных» и находиться на первой странице.
sberbank ответил:
… конструктивные жалобы — это подарок для нас. Из похвального отзыва не вынести столько полезного и не улучшить качества сервиса. Уже на ближайшей встрече в субботу будем обсуждать с IT-департаментом полученные жалобы с хабра.
Я очень благодарна всем, кто помогает нам стать лучше. Спасибо!
Прошло 4 месяца.
Я сегодня начну процесс перевода стипендии и зарплаты в университете с карточки сбербанка в другой, адекватный банк. Я отдаю себе отчёт в том, как меня затрахают тётушки в бухгалтерии. Но мне надоел этот хамский сервис, это наплевательское отношение к своей работе, вечно неработающие банкоматы и отключение процессинговых центров в будний день. Я голосую рублём.
forgotten был прав, на Сбербанке с его текущим руководством можно ставить крест.
upd: кто-то целенаправленно меня сливает, скоро я не смогу ответить на комментарии, извините.
02.06.2011 11:03+0400
Язолъ →
Яндекс.Деньги теперь позволяет удалить старый счет и создать новый
Неожиданное продолжение получила моя недавняя история.
Только что пришло письмо от Яндекс.Деньги, где говорится, что я могу удалить свой старый счет и создать новый под тем же логином. Какой приятный сюрприз!..
Только что пришло письмо от Яндекс.Деньги, где говорится, что я могу удалить свой старый счет и создать новый под тем же логином. Какой приятный сюрприз!..
01.06.2011 20:08+0400
Песочница →
Про день ЗПДн или как работать с персональными данными в белую — 3
Хай, Хабр!
Продолжаем обзор этапов подготовки к 1 июля – Дню защиты персональных данных. В первой статье мы создавали комиссию, во второй – проводили классификацию нашей ИСПДн. Настало время вступить в сообщество благоразумных и законопослушных специалистов, коих уже как минимум 197 тысяч. Точнее сказать — внести запись о своей ИСПДн в реестр операторов персональных данных, в котором уже числятся 197 487 компаний и организаций… упс, уже 197 646. Инвайтом для вступления, точнее пропуском в реестр станет заполненная на портале Роскомнадзора форма «Уведомления об обработке персональных данных». Важно понимать, что с момента отжатия кнопки «Отправить» мы по своей доброй воле объявим свою организацию оператором персональных и будем вынуждены соответствовать букве закона. С одной стороны, в этом есть некоторые риски, авось про нас никто и никогда бы не вспомнил? Может и так, но с другой стороны, если, не имея уважительных причин не направим уведомление до 30 июня исключительно, то уже с первого июля наша компания станет нарушителем 152-ФЗ и эта дата станет точкой невозврата.
Продолжаем обзор этапов подготовки к 1 июля – Дню защиты персональных данных. В первой статье мы создавали комиссию, во второй – проводили классификацию нашей ИСПДн. Настало время вступить в сообщество благоразумных и законопослушных специалистов, коих уже как минимум 197 тысяч. Точнее сказать — внести запись о своей ИСПДн в реестр операторов персональных данных, в котором уже числятся 197 487 компаний и организаций… упс, уже 197 646. Инвайтом для вступления, точнее пропуском в реестр станет заполненная на портале Роскомнадзора форма «Уведомления об обработке персональных данных». Важно понимать, что с момента отжатия кнопки «Отправить» мы по своей доброй воле объявим свою организацию оператором персональных и будем вынуждены соответствовать букве закона. С одной стороны, в этом есть некоторые риски, авось про нас никто и никогда бы не вспомнил? Может и так, но с другой стороны, если, не имея уважительных причин не направим уведомление до 30 июня исключительно, то уже с первого июля наша компания станет нарушителем 152-ФЗ и эта дата станет точкой невозврата.
01.06.2011 11:52+0400
Ни о чём →
На работу в Чехию
 В последнее время ко мне участились обращения от знакомых и незнакомых людей с просьбой рассказать, как можно уехать на работу в Чехию. Поэтому я решил написать об этом на Хабре, авось ещё кому пригодится, да и сам буду отмахиваться от последующих обращений данным текстом.
В последнее время ко мне участились обращения от знакомых и незнакомых людей с просьбой рассказать, как можно уехать на работу в Чехию. Поэтому я решил написать об этом на Хабре, авось ещё кому пригодится, да и сам буду отмахиваться от последующих обращений данным текстом.Начать бы хотелось с главного: времена, когда эмигрировать в Чехию было очень просто, похоже, уходят окончательно. И теперь сюда попасть почти такой же гемор, как и любую другую страну Шенгена. А, если нет разницы, почему бы не уехать в страны побогаче (Германия, Франция и т. п.)? Ах, вам нравится чешское пиво и тихая, размеренная жизнь? Тогда прошу под кат.
31.05.2011 20:14+0400
latex →
Вёрстка газет в LaTeX
Для начала оговорюсь, что я — не профессиональный верстальщик, на моей совести всего две газеты общим тиражом всех номеров меньше тысячи экземпляров. Я просто хочу лишь показать некоторые возможности пакета LaTeX.
Без дальнейших предисловий — представляю вам этот PDF файл. Легко ли такое сделать в Word?
Без дальнейших предисловий — представляю вам этот PDF файл. Легко ли такое сделать в Word?
31.05.2011 17:48+0400
Ни о чём →
Клиент для Lenta.ru под Android
Часто читаю новости Lenta.ru в метро. Заголовков из их RSS-канала недостаточно, а читать полные статьи в браузере — не совсем удобно. В Android Market нашелся достойный клиент, но мне захотелось написать более простое и удобное в навигации приложение. Возможно, кому-то из сообщества оно будет интересно.

Главный экран приложения накапливает новости из RSS-канала издания и показывает 40 последних статей. Статьи кэшируются полностью (включая текст статьи с сайта), поэтому достаточно обновится один раз и читать новости в подземке. Уже после загрузки всех статей, клиент скачивает небольшие эскизы, которые дают представление о содержимом конкретной статьи. В отличие от текстов, картинки для статей подгружаются по мере доступа к ним пользователя. Если Вам не интересна какая-либо статья, Вы просто ее не откроете и сэкономите трафик на загрузке картинки.
Новые и прочитанные статьи выделяются для наглядности. Есть возможность регулирования размера шрифта для удобства чтения. Также можно поделиться любой статьей с друзьями.
Чтобы сократить расходы на трафик, в настройках можно отключить загрузку эскизов и/или картинок. Если необходимо освободить немного места на SD-карте, можно очистить кэш (эскизы и картинки) прямо из приложения.
Программа бесплатна и доступна в Android Market. Резюмируя, можно отметить следующие ее особенности:
Скачать с Android Market

Главный экран приложения накапливает новости из RSS-канала издания и показывает 40 последних статей. Статьи кэшируются полностью (включая текст статьи с сайта), поэтому достаточно обновится один раз и читать новости в подземке. Уже после загрузки всех статей, клиент скачивает небольшие эскизы, которые дают представление о содержимом конкретной статьи. В отличие от текстов, картинки для статей подгружаются по мере доступа к ним пользователя. Если Вам не интересна какая-либо статья, Вы просто ее не откроете и сэкономите трафик на загрузке картинки.
Новые и прочитанные статьи выделяются для наглядности. Есть возможность регулирования размера шрифта для удобства чтения. Также можно поделиться любой статьей с друзьями.
Чтобы сократить расходы на трафик, в настройках можно отключить загрузку эскизов и/или картинок. Если необходимо освободить немного места на SD-карте, можно очистить кэш (эскизы и картинки) прямо из приложения.
Программа бесплатна и доступна в Android Market. Резюмируя, можно отметить следующие ее особенности:
- простой и интуитивный пользовательский интерфейс;
- быстрая загрузка статей;
- полнотекстовые статьи с картинками;
- регулируемый размер шрифта;
- возможность делиться новостями с друзьями;
- настройки: включение/отключение загрузки картинок;
- настройки: очистка кэша.
Скачать с Android Market
31.05.2011 16:17+0400
Ни о чём →
Обучающий рэп от Google
Возможно некоторым хабражителям будет интересно посмотерть, как доходчиво гугл объясняет, как пользоваться его справкой. Топик-ссылку опубликовать не могу, поэтому здесь привожу просто ссылку на это видео:
docs.google.com/support/bin/answer.py?answer=181336
Нарочно не встраиваю видео сюда, т.к. его лучше смотреть на сайте справки :-)
docs.google.com/support/bin/answer.py?answer=181336
Нарочно не встраиваю видео сюда, т.к. его лучше смотреть на сайте справки :-)
30.05.2011 21:32+0400
Реклама →
Баннерная слепота
30.05.2011 15:10+0400
Реклама →
Приглашение к публичному обсуждению рейтинга CMS по usability
30.05.2011 14:20+0400
Научно популярное →
В пятницу было официально завершено конструирование МКС

Другими словами, в пятницу космонавты выполнили последнюю по плану работу на Международной Космической Станции, присоединив к станции последний модуль (нечто вроде оснащенного лазером крана) для роботизированного манипулятора. Таким образом, спустя 13 лет и 35-100 миллиардов долларов (точная сумма неизвестна), орбитальная космическая станция полностью готова. Она работала и раньше, это знаем мы все, но работы, выполненные космонавтами в прошлую пятницу, являются финальной стадией по завершению конструирования МКС. Правда, в 2012 году к МКС может быть (и скорее всего будет) присоединен русский модуль «Наука». Под катом еще немного
Это будет последнее крупное обновление станции, но уже как бы внеплановое. К слову, во время проведения работ был побит еще один рекорд — около 1000 часов работ в космическом пространстве.
Вполне может быть, что уже в ближайшее время будет объявлено о возможности присоединения к станции различных модулей сторонних организаций (в том числе и тех, что занимаются космическим туризмом). В общем-то, простор для конструкторской мысли есть, были бы только деньги для выполнения всего задуманного. К слову, недавно NASA возобновила работы по созданию космического корабля, который вполне сможет долететь до Луны и Марса, высадив новое поколение исследователей. Ранее работы в этом направлении были свернуты, поскольку США официально свернуло лунную программу. Возобновление работы, возможно, свидетельствует о намерении этой страны разморозить программу.
Что же, будем надеяться, что МКС сможет проработать еще много времени (кстати, кто знает, сколько выделили конструкторы времени на работу этой станции?).






Via Yahoo
30.05.2011 13:25+0400
Ни о чём →
Наивный Байесовский классификатор в 25 строк кода
Наивный Байесовский классификатор один из самых простых из алгоритмов классификации. Тем не менее, очень часто он работает не хуже, а то и лучше более сложных алгоритмов. Здесь я хочу поделиться кодом и описанием того, как это все работает.
И так, для примера возьму задачу определения пола по имени. Конечно, чтобы определить пол можно создать большой список имен с метками пола. Но этот список в любом случае будет неполон. Для того чтобы решить эту проблему, можно «натренировать» модель по маркированным именам.
Если интересует, прошу .
Пусть у нас есть строка текста O. Кроме того, имеются классы С, к одному из которых мы должны отнести строку. Нам необходимо найти такой класс с, при котором его вероятность для данной строки была бы максимальна. Математически это записывается так:
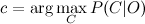
Вычислить P(C|O) сложно. Но можно воспользоваться теоремой Байеса и перейти к косвенным вероятностям:
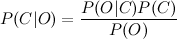
Так как мы ищем максимум от функции, то знаменатель нас не интересует (он в данном случае константа). Кроме того, нужно взглянуть на строку O. Обычно, нет смысла работать со всей строкой. Намного эффективней выделить из нее определенные признаки (features). Таким образом формула примет вид:
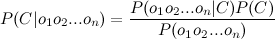
Знаменатель нас не интересует. Числитель же можно переписать так.

Но это опять сложно. Здесь включаем «наивное» предположение о том, что переменные O зависят только от класса C, и не зависят друг от друга. Это сильно упрощение, но зачастую это работает. Числитель примет вид:
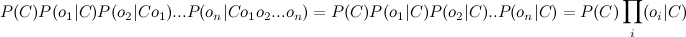
Финальная формула примет вид:
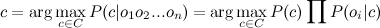
Т.е. все что нужно сделать, это вычислить вероятности P( C ) и P(O|C). Вычисление этих параметров и называется тренировкой классификатора.
Ниже — код на питоне. Содержит всего две функции: одна для тренировки (подсчета параметров формулы), другая для классификации (непосредственный расчет формулы).
Чтобы натренировать протестировать классификатор возьмем размеченный список мужских и женских имен и воспользуемся этим кодом.
Файл 'names.txt' можно скачать здесь.
В качестве фич я выбрал последнюю букву имени (см функцию get_features). Работает неплохо, но для рабочего варианта лучше использовать схему посложнее. К примеру, выбрать первую букву имени и две последних. К примеру, вот так:
Я протестировал классификатор на части исходного корпуса с именами. Точность составила 96%. Это не блестящий результат, но для многих задач вполне достаточно.
И так, для примера возьму задачу определения пола по имени. Конечно, чтобы определить пол можно создать большой список имен с метками пола. Но этот список в любом случае будет неполон. Для того чтобы решить эту проблему, можно «натренировать» модель по маркированным именам.
Если интересует, прошу .
Немного теории
Пусть у нас есть строка текста O. Кроме того, имеются классы С, к одному из которых мы должны отнести строку. Нам необходимо найти такой класс с, при котором его вероятность для данной строки была бы максимальна. Математически это записывается так:
Вычислить P(C|O) сложно. Но можно воспользоваться теоремой Байеса и перейти к косвенным вероятностям:
Так как мы ищем максимум от функции, то знаменатель нас не интересует (он в данном случае константа). Кроме того, нужно взглянуть на строку O. Обычно, нет смысла работать со всей строкой. Намного эффективней выделить из нее определенные признаки (features). Таким образом формула примет вид:
Знаменатель нас не интересует. Числитель же можно переписать так.
Но это опять сложно. Здесь включаем «наивное» предположение о том, что переменные O зависят только от класса C, и не зависят друг от друга. Это сильно упрощение, но зачастую это работает. Числитель примет вид:
Финальная формула примет вид:
Т.е. все что нужно сделать, это вычислить вероятности P( C ) и P(O|C). Вычисление этих параметров и называется тренировкой классификатора.
Код
Ниже — код на питоне. Содержит всего две функции: одна для тренировки (подсчета параметров формулы), другая для классификации (непосредственный расчет формулы).
from __future__ import division
from collections import defaultdict
from math import log
def train(samples):
classes, freq = defaultdict(lambda:0), defaultdict(lambda:0)
for feats, label in samples:
classes[label] += 1 # count classes frequencies
for feat in feats:
freq[label, feat] += 1 # count features frequencies
for label, feat in freq: # normalize features frequencies
freq[label, feat] /= classes[label]
for c in classes: # normalize classes frequencies
classes[c] /= len(samples)
return classes, freq # return P© and P(O|C)
def classify(classifier, feats):
classes, prob = classifier
return min(classes.keys(), # calculate argmin(-log(C|O))
key = lambda cl: -log(classes[cl]) + \
sum(-log(prob.get((cl,feat), 10**(-7))) for feat in feats))
Чтобы натренировать протестировать классификатор возьмем размеченный список мужских и женских имен и воспользуемся этим кодом.
def get_features(sample): return (sample[-1],) # get last letter
samples = (line.decode('utf-8').split() for line in open('names.txt'))
features = [(get_features(feat), label) for feat, label in samples]
classifier = train(features)
print 'gender: ', classify(classifier, get_features(u'Аглафья'))
Файл 'names.txt' можно скачать здесь.
В качестве фич я выбрал последнюю букву имени (см функцию get_features). Работает неплохо, но для рабочего варианта лучше использовать схему посложнее. К примеру, выбрать первую букву имени и две последних. К примеру, вот так:
def get_features(sample): return (
'll: %s' % sample[-1], # get last letter
'fl: %s' % sample[1], # get first letter
'sl: %s' % sample[0], # get second letter
)
Тесты
Я протестировал классификатор на части исходного корпуса с именами. Точность составила 96%. Это не блестящий результат, но для многих задач вполне достаточно.
30.05.2011 01:33+0400
Биотехнологии →
Харви Файнберг: Готовы ли вы к неоэволюции?
Специалист по этике медицины Харви Файнберг показывает нам три пути развития постоянно эволюционирующего человеческого вида:
Неоэволюция вполне возможна.
Как мы поступим с этой возможностью?
- Прекратить эволюционировать полностью
- Эволюционировать естественно
- Контролировать следующие этапы нашей эволюции, используя генетические модификации, чтобы сделать нас умнее, быстрее, лучше.
Неоэволюция вполне возможна.
Как мы поступим с этой возможностью?
29.05.2011 21:18+0400
Биотехнологии →
Харви Файнберг: Готовы ли вы к неоэволюции?
Специалист по этике медицины Харви Файнберг показывает нам три пути развития постоянно эволюционирующего человеческого вида:
Неоэволюция вполне возможна.
Как мы поступим с этой возможностью?
- Прекратить эволюционировать полностью
- Эволюционировать естественно
- Контролировать следующие этапы нашей эволюции, используя генетические модификации, чтобы сделать нас умнее, быстрее, лучше.
Неоэволюция вполне возможна.
Как мы поступим с этой возможностью?
29.05.2011 21:18+0400