
machine learning
Найдено: 1 запись
Ни о чём →
Наивный Байесовский классификатор в 25 строк кода
Наивный Байесовский классификатор один из самых простых из алгоритмов классификации. Тем не менее, очень часто он работает не хуже, а то и лучше более сложных алгоритмов. Здесь я хочу поделиться кодом и описанием того, как это все работает.
И так, для примера возьму задачу определения пола по имени. Конечно, чтобы определить пол можно создать большой список имен с метками пола. Но этот список в любом случае будет неполон. Для того чтобы решить эту проблему, можно «натренировать» модель по маркированным именам.
Если интересует, прошу .
Пусть у нас есть строка текста O. Кроме того, имеются классы С, к одному из которых мы должны отнести строку. Нам необходимо найти такой класс с, при котором его вероятность для данной строки была бы максимальна. Математически это записывается так:
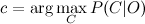
Вычислить P(C|O) сложно. Но можно воспользоваться теоремой Байеса и перейти к косвенным вероятностям:
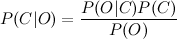
Так как мы ищем максимум от функции, то знаменатель нас не интересует (он в данном случае константа). Кроме того, нужно взглянуть на строку O. Обычно, нет смысла работать со всей строкой. Намного эффективней выделить из нее определенные признаки (features). Таким образом формула примет вид:
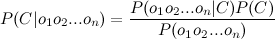
Знаменатель нас не интересует. Числитель же можно переписать так.

Но это опять сложно. Здесь включаем «наивное» предположение о том, что переменные O зависят только от класса C, и не зависят друг от друга. Это сильно упрощение, но зачастую это работает. Числитель примет вид:
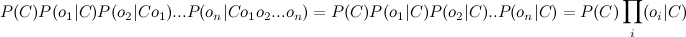
Финальная формула примет вид:
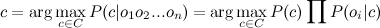
Т.е. все что нужно сделать, это вычислить вероятности P( C ) и P(O|C). Вычисление этих параметров и называется тренировкой классификатора.
Ниже — код на питоне. Содержит всего две функции: одна для тренировки (подсчета параметров формулы), другая для классификации (непосредственный расчет формулы).
Чтобы натренировать протестировать классификатор возьмем размеченный список мужских и женских имен и воспользуемся этим кодом.
Файл 'names.txt' можно скачать здесь.
В качестве фич я выбрал последнюю букву имени (см функцию get_features). Работает неплохо, но для рабочего варианта лучше использовать схему посложнее. К примеру, выбрать первую букву имени и две последних. К примеру, вот так:
Я протестировал классификатор на части исходного корпуса с именами. Точность составила 96%. Это не блестящий результат, но для многих задач вполне достаточно.
И так, для примера возьму задачу определения пола по имени. Конечно, чтобы определить пол можно создать большой список имен с метками пола. Но этот список в любом случае будет неполон. Для того чтобы решить эту проблему, можно «натренировать» модель по маркированным именам.
Если интересует, прошу .
Немного теории
Пусть у нас есть строка текста O. Кроме того, имеются классы С, к одному из которых мы должны отнести строку. Нам необходимо найти такой класс с, при котором его вероятность для данной строки была бы максимальна. Математически это записывается так:
Вычислить P(C|O) сложно. Но можно воспользоваться теоремой Байеса и перейти к косвенным вероятностям:
Так как мы ищем максимум от функции, то знаменатель нас не интересует (он в данном случае константа). Кроме того, нужно взглянуть на строку O. Обычно, нет смысла работать со всей строкой. Намного эффективней выделить из нее определенные признаки (features). Таким образом формула примет вид:
Знаменатель нас не интересует. Числитель же можно переписать так.
Но это опять сложно. Здесь включаем «наивное» предположение о том, что переменные O зависят только от класса C, и не зависят друг от друга. Это сильно упрощение, но зачастую это работает. Числитель примет вид:
Финальная формула примет вид:
Т.е. все что нужно сделать, это вычислить вероятности P( C ) и P(O|C). Вычисление этих параметров и называется тренировкой классификатора.
Код
Ниже — код на питоне. Содержит всего две функции: одна для тренировки (подсчета параметров формулы), другая для классификации (непосредственный расчет формулы).
from __future__ import division
from collections import defaultdict
from math import log
def train(samples):
classes, freq = defaultdict(lambda:0), defaultdict(lambda:0)
for feats, label in samples:
classes[label] += 1 # count classes frequencies
for feat in feats:
freq[label, feat] += 1 # count features frequencies
for label, feat in freq: # normalize features frequencies
freq[label, feat] /= classes[label]
for c in classes: # normalize classes frequencies
classes[c] /= len(samples)
return classes, freq # return P© and P(O|C)
def classify(classifier, feats):
classes, prob = classifier
return min(classes.keys(), # calculate argmin(-log(C|O))
key = lambda cl: -log(classes[cl]) + \
sum(-log(prob.get((cl,feat), 10**(-7))) for feat in feats))
Чтобы натренировать протестировать классификатор возьмем размеченный список мужских и женских имен и воспользуемся этим кодом.
def get_features(sample): return (sample[-1],) # get last letter
samples = (line.decode('utf-8').split() for line in open('names.txt'))
features = [(get_features(feat), label) for feat, label in samples]
classifier = train(features)
print 'gender: ', classify(classifier, get_features(u'Аглафья'))
Файл 'names.txt' можно скачать здесь.
В качестве фич я выбрал последнюю букву имени (см функцию get_features). Работает неплохо, но для рабочего варианта лучше использовать схему посложнее. К примеру, выбрать первую букву имени и две последних. К примеру, вот так:
def get_features(sample): return (
'll: %s' % sample[-1], # get last letter
'fl: %s' % sample[1], # get first letter
'sl: %s' % sample[0], # get second letter
)
Тесты
Я протестировал классификатор на части исходного корпуса с именами. Точность составила 96%. Это не блестящий результат, но для многих задач вполне достаточно.
30.05.2011 01:33+0400