
Песочница →
Cкоростная синхронизация миллиарда файлов
Есть несколько идентичных серверов (4 ноды) на Amazon EC2. Каждый генерирует и хранит у себя на диске кэш, который хотелось бы синхронизировать. Но простой rsync тут не подойдет — файлов несколько миллиардов, nfs — слишком медлителен, и т. д. Полный список рассмотренных вариантов с пояснениями ниже.
К тому же, время от времени нужно удалять устаревшие файлы сразу на всех серверах, что пока делается вручную и занимает несколько суток. Вопрос наиболее быстрой для такого Use Case файловой системы планирую описать позже. Оговорюсь только, что по нескольким причинам была выбрана XFS.
После теста нескольких кластерных технологий и файловых систем, по совету старшего товарища, решили использовать тот же rsync, но в связке с inotify. Немного поискав в интернете готовое такое решение, дабы не изобретать велосипед, наткнулся на csyncd, inosync и lsyncd. На хабре уже была статья о csyncd, но он тут не подходит, т.к. хранит список файлов в базе SQLite, которая вряд-ли сможет сносно работать даже с миллионом записей. Да и лишнее звено при таких объемах ни к чему. А вот lsyncd оказался именно тем, что нам и было нужно.
Lsyncd — демон, который следит за изменениями в локальной директории, аггрегирует их, и по прошествии определенного времени стартует rsync для их синхронизации.
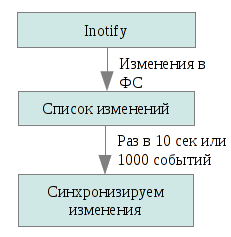
Итак, rsync'ать все сразу мы не можем, зато можем обновлять только то, что изменилось. О последнем нам расскажет inotify, подсистема ядра, уведомляющий приложения об изменениях в файловой системе. Lsyncd следит за событиями изменения локального дерева файлов, собирает эту информацию за 10 секунд (можно указать любое другое время) либо пока не соберется 1000 событий (смотря какое событие произойдет первым), и запускает rsync для отправки этих файлов на остальные ноды в нашем кластере. Запускается rsync с параметром update, то есть файл на получателе будет заменен отправляемым только если последний новее. Это дает возможность избежать коллизий и лишних операций (например, если один и тот же файл был сгенерирован парралельно и на отправителе, и на получателе).
Процесс установки описан для Ubuntu 11.10. В других версиях могут быть отличия.
1. Настроим ssh, чтобы можно было зайти с любой ноды на другую без авторизации. Скорее всего все знают как это делается, но на всякий случай опишу.
Passphrase оставляем пустой.
Далее добавляем содержимое ~/.ssh/id_rsa.pub на все остальные ноды в кластере в ~/.ssh/authorized_keys. Естественно выбераем $HOME того пользователя, который имеет права на запись в папку синхронизации. Проще всего, если это будет /root, но это не лучший выбор с точки зрения безопасности.
Желательно также прописать все ноды в /etc/hosts. Я назвал их node01, node02, node03.
Повторяем на всех нодах.
2. Устанавливаем lsyncd
3. Конфиг хоть и нужно создавать вручную, но он довольно прост. Пишется на языке Lua. Интересен также комментарий о причинах выбора именно Lua от автора lsyncd. Я еще создал отдельную директорию для логов.
Содержимое конфига с комментариями:
settings = {
logfile = "/var/log/lsyncd/lsyncd.log",
statusFile = "/var/log/lsyncd/lsyncd.status",
nodaemon = true --<== лучше оставить для дебага. потом выключите.
}
--[[
sync {
default.rsync, --<== используем rsync для синхронизации. по-идее, можно использовать и что-то другое.
source="/raid", --<== локальная директория, которую синхронизируем
target=«node01:/raid», --<== dns-имя и директория на ноде-получателе через двоеточие
rsyncOps={"-ltuspog", "--temp-dir=/mnt-is"}, --<== temp-dir нужна если синхронизация двухсторонняя.
delay=10 --<== время, которое будет собираться список событий для синхронизации
}
]]
sync {
default.rsync,
source="/raid",
target=«node02:/raid»,
rsyncOps={"-ltuspog", "--temp-dir=/mnt-is"},
delay=10
}
sync {
default.rsync,
source="/raid",
target=«node03:/raid»,
rsyncOps={"-ltuspog", "--temp-dir=/mnt-is"},
delay=10
}
Конфиг проще сделать один раз и дальше разнести на все ноды, закомментировав лишний для каждого конкретного сервера блок. Комментарии — все что находится между «--[[» и «]]».
Используемые опции вызова rsync:
l — копировать симлинки;
u — не обновлять файлы на получателе если они новее;
t,p,o,g — копировать время, права доступа, владельца, группу соответственно.
s — на случай если в имени файла попадется пробел.
Подробнее в man lsyncd или в документации.
4. Стартуем демон на всех нодах:
Если Вы оставили «nodaemon = true» в конфиге, то сможете видеть что происходит.
Дальше копируем/создаем/удаляем что-нибудь в директории, которую мы указали для синхронизации (у мнея это /raid), ждем несколько секунд и проверяем результат синхронизации.
Скорость передачи данных достигает 300 Мбит/с и на загрузку сервера это мало влияет (по сравнению с тем же GlusterFS, например), да и задержка в данном случае сглаживает пики. Многое еще зависит от используемой ФС. Тут тоже пришлось провести маленькое исследование, с цифрами и графиками, так как ситуация довольно специфическая и результаты существующих опубликованных тестов не отражают того, что требуется в задаче.
Все исследование было нацелено на работу с Amazon EC2, с учетом ее ограничений и особенностей, поэтому полученные выводы в основном касаются только ее.
Спасибо за внимание!
К тому же, время от времени нужно удалять устаревшие файлы сразу на всех серверах, что пока делается вручную и занимает несколько суток. Вопрос наиболее быстрой для такого Use Case файловой системы планирую описать позже. Оговорюсь только, что по нескольким причинам была выбрана XFS.
После теста нескольких кластерных технологий и файловых систем, по совету старшего товарища, решили использовать тот же rsync, но в связке с inotify. Немного поискав в интернете готовое такое решение, дабы не изобретать велосипед, наткнулся на csyncd, inosync и lsyncd. На хабре уже была статья о csyncd, но он тут не подходит, т.к. хранит список файлов в базе SQLite, которая вряд-ли сможет сносно работать даже с миллионом записей. Да и лишнее звено при таких объемах ни к чему. А вот lsyncd оказался именно тем, что нам и было нужно.
Rsync + inotify = lsyncd
Lsyncd — демон, который следит за изменениями в локальной директории, аггрегирует их, и по прошествии определенного времени стартует rsync для их синхронизации.
Итак, rsync'ать все сразу мы не можем, зато можем обновлять только то, что изменилось. О последнем нам расскажет inotify, подсистема ядра, уведомляющий приложения об изменениях в файловой системе. Lsyncd следит за событиями изменения локального дерева файлов, собирает эту информацию за 10 секунд (можно указать любое другое время) либо пока не соберется 1000 событий (смотря какое событие произойдет первым), и запускает rsync для отправки этих файлов на остальные ноды в нашем кластере. Запускается rsync с параметром update, то есть файл на получателе будет заменен отправляемым только если последний новее. Это дает возможность избежать коллизий и лишних операций (например, если один и тот же файл был сгенерирован парралельно и на отправителе, и на получателе).
Реализация
Процесс установки описан для Ubuntu 11.10. В других версиях могут быть отличия.
1. Настроим ssh, чтобы можно было зайти с любой ноды на другую без авторизации. Скорее всего все знают как это делается, но на всякий случай опишу.
# ssh-keygenPassphrase оставляем пустой.
Далее добавляем содержимое ~/.ssh/id_rsa.pub на все остальные ноды в кластере в ~/.ssh/authorized_keys. Естественно выбераем $HOME того пользователя, который имеет права на запись в папку синхронизации. Проще всего, если это будет /root, но это не лучший выбор с точки зрения безопасности.
Желательно также прописать все ноды в /etc/hosts. Я назвал их node01, node02, node03.
Повторяем на всех нодах.
2. Устанавливаем lsyncd
#apt-get install lsyncd3. Конфиг хоть и нужно создавать вручную, но он довольно прост. Пишется на языке Lua. Интересен также комментарий о причинах выбора именно Lua от автора lsyncd. Я еще создал отдельную директорию для логов.
# mkdir -p /etc/lsyncd
# mkdir -p /var/log/lsyncd
# vi /etc/lsyncd/lsyncd.conf.luaСодержимое конфига с комментариями:
settings = {
logfile = "/var/log/lsyncd/lsyncd.log",
statusFile = "/var/log/lsyncd/lsyncd.status",
nodaemon = true --<== лучше оставить для дебага. потом выключите.
}
--[[
sync {
default.rsync, --<== используем rsync для синхронизации. по-идее, можно использовать и что-то другое.
source="/raid", --<== локальная директория, которую синхронизируем
target=«node01:/raid», --<== dns-имя и директория на ноде-получателе через двоеточие
rsyncOps={"-ltuspog", "--temp-dir=/mnt-is"}, --<== temp-dir нужна если синхронизация двухсторонняя.
delay=10 --<== время, которое будет собираться список событий для синхронизации
}
]]
sync {
default.rsync,
source="/raid",
target=«node02:/raid»,
rsyncOps={"-ltuspog", "--temp-dir=/mnt-is"},
delay=10
}
sync {
default.rsync,
source="/raid",
target=«node03:/raid»,
rsyncOps={"-ltuspog", "--temp-dir=/mnt-is"},
delay=10
}
Конфиг проще сделать один раз и дальше разнести на все ноды, закомментировав лишний для каждого конкретного сервера блок. Комментарии — все что находится между «--[[» и «]]».
Используемые опции вызова rsync:
l — копировать симлинки;
u — не обновлять файлы на получателе если они новее;
t,p,o,g — копировать время, права доступа, владельца, группу соответственно.
s — на случай если в имени файла попадется пробел.
Подробнее в man lsyncd или в документации.
4. Стартуем демон на всех нодах:
# /etc/init.d/lsyncd startЕсли Вы оставили «nodaemon = true» в конфиге, то сможете видеть что происходит.
Дальше копируем/создаем/удаляем что-нибудь в директории, которую мы указали для синхронизации (у мнея это /raid), ждем несколько секунд и проверяем результат синхронизации.
Скорость передачи данных достигает 300 Мбит/с и на загрузку сервера это мало влияет (по сравнению с тем же GlusterFS, например), да и задержка в данном случае сглаживает пики. Многое еще зависит от используемой ФС. Тут тоже пришлось провести маленькое исследование, с цифрами и графиками, так как ситуация довольно специфическая и результаты существующих опубликованных тестов не отражают того, что требуется в задаче.
Что еще было рассмотрено и почему не подходит в данном случае
Все исследование было нацелено на работу с Amazon EC2, с учетом ее ограничений и особенностей, поэтому полученные выводы в основном касаются только ее.
- DRBD – репликация идет на блочном уровне. В случае деградации одного носителя убиваются оба. Ограничение в 2 ноды. (Больше можно, но 3 и 4-й можно подключить только как слейвы.)
- Ocfs2 – используется либо поверх DRBD (о чем есть хорошая статья на хабре), либо нужно иметь возможность монтировать один раздел с нескольких нод. Невозможно на ec2.
- Gfs2 – аналог ocfs2. Не пробовал, т. к. согласно тестам эта ФС медленней ocfs2, в остальном — ее аналог.
- GlusterFS – вот тут все заработало практически сразу и как надо! Проста и логична в администрировании. Можно сделать кластер до 255 нод с произвольным значением реплик. Создал кластерный раздел из пары серверов и примонтировал его на них же но в другую директорию (то есть сервера были одновременно и клиентами). К сожалению на клиенте этот кластер монтируется через FUSE, и скорость записи оказалась ниже 3 МБ/сек. А так, впечатления от использования очень хорошие.
- Lustre — чтобы запустить сие дело в krenel mode нужно патчить ядро. Как ни странно, в репозитории Ubuntu есть пакет с этими патчами, но вот самих патчей под нее или хотя-бы под Debian я не нашел. И судя по отзывам, понял, что завести это в deb-системе — шаманство.
- Hadoop w/ HDFS, Cloudera — не пробовал, поскольку было найдено другое решение (см. ниже). Но первое что бросается в глаза — написано на Java, следовательно ресурсов кушать будет много, да и масштабы не как у Фесбука или Яху, всего 4 ноды пока.
Спасибо за внимание!
08.11.2011 03:18+0400