
Разбирая данные →
Системы рекомендаций: холодное начало
Системы рекомендаций:
— Советы от машины
— Холодное начало
— Введение в гибридные системы
— искусственные имунные системы и эффект идиотипов
Для успешного применения систем рекомендаций критически важно иметь большой объем справочных данных. Но что делать, если нужных данных совсем нет, или не достаточно? Такое состояние называется холодным началом (cold start). Например, на сайте зарегистрировался новый пользователь, и система еще ничего о нем не знает. Или в магазине появился новый товар, который никто никогда не покупал и не оценивал. Или совсем плохо, система только начала свою работу и данных у нее нет вообще. Посмотрим, что можно сделать в таких ситуациях.
Если система рекомендаций — это только одна из возможностей вашего сервиса, то вы можете развлекать пользователя другими функциями, пока система не соберет необходимые ей данные. Необходимое для этого время напрямую зависит от активности пользователя. Вряд ли его можно точно рассчитать, но важно представлять себе, в каких примерно рамках оно лежит.
Для систем, собирающих данные открыто, этот процесс в некоторых случая можно ускорить, дав пользователю возможность активно «дрессировать» систему. Можно частично открыть принципы работы системы и данные, которые она использует, это поможет более шустрым пользователям быстро настроить систему под себя.
Некоторую информацию о пользователе можно выловить за пределами вашего сайта. Кое-что можно узнать, проанализировав его историю посещений других сайтов, уделяя особенное внимание поисковым запросам (полезно будет ознакомиться со статьей "Определение пола по истории навигации" как хорошим примером анализа истории). Имея некоторые личные данные о пользователе, например, его email, можно найти информацию о нем в его блоге или социальных сетях. Благо, множество сервисов обеспечивают открытый доступ к информации через API. Полученные в результате данные можно использовать по отдельности, или отнести пользователя к какому-нибудь стереотипу и сделать предположение о других его качествах.
При создании системы подумайте, какие дополнительные источники информации будут для нее доступны, возможно какие-то из них стоит использовать. Эти методы могут быть достаточно трудоемкими и вполне возможно, что данные придется собирать по крупицам, но если для системы важно знать как о пользователе как можно больше и как можно быстрее, то они могут помочь.
Следующие два метода дают более объективные результаты. Их суть в том, что мы можем попытаться предсказать отношение пользователя к новому объекту, основываясь на том, как он оценивал другие объекты, и как новый объект оценили другие пользователи.
Для примера возьмем один из алгоритмов коллективной фильтрации — Slope One. Для предсказания рейтинга он использует среднюю разницу между объектом, оценку которого система пытается определить, и объектом, оценку которого она уже знает.
Допустим, у нас есть некоторые данные о том, кто как оценил товар:
Зная, какая средняя разница между оценками товара А и Б, мы можем вычислить оценку Саши для товара Б:
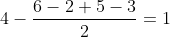
Хотя метод достаточно грубый, он работает.
Второй достаточно простой, но очень элегантный и эффективный метод заключается в том, чтобы представить сравниваемые объекты в виде многомерных векторов, где в качестве координат используется численное представление некоторых его свойств. Тогда величиной, характеризующей сходство этих объектов будет косинус угла между векторами. Обозначим вектора A и B, тогда косинус угла между ними равен (по определению скалярного произведения):
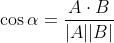
где A*B — скалярное произведение векторов, а |A||B| — произведение их модулей.
Очевидно, что в результате мы получим число от -1 до 1 включительно (от 0 до 1, если оба вектора положительны). Число 1 значит, что вектора направлены одинаково, и объекты идентичны; 0 значит, что вектора ортогональны (перпендикулярны), и объекты не имеют ничего общего; -1 — что вектора направлены в противоположные стороны, и наши объекты тоже противоположны.
В качестве координат вектора можно использовать любые параметры, по которым можно сравнивать два объекта и которые можно представить в численном виде. Например, если нам надо сравнить два текста, то за измерения мы можем принять встречающиеся в них слова, а за координаты — количество их использований в тексте (хотя лучше использовать их релевантность слова к тексту, полученную, например, методом TD-IDF). Более подробно о представлении текстов в виде векторов можно прочитать в статье "Vector space model", а в статье про Slope One есть пример использование вектора с бинарными величинами.
Вернемся к нашему примеру, и попытаемся определить оценку Артура товару В, на основе сходства его мнения с Катей. В виде векторов мы представим Артура и Катю, в качестве измерений используем товары, а координатами послужат их оценки. Тогда:
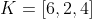
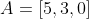
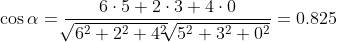
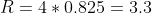
Очевидно, что для подобной оценки лучше брать посетителей, мнения которых совпадают.
В проекте moismi.ru я использовал этот алгоритм для поиска похожих тегов. Вот несколько наглядных примеров эффективности векторной модели (внимание на облако тегов в правой части сайта): "Microsoft", "браузер", "Google". Несколько хуже он работает для более редких тегов.
Оригинал на моем блоге
— Советы от машины
— Холодное начало
— Введение в гибридные системы
— искусственные имунные системы и эффект идиотипов
Для успешного применения систем рекомендаций критически важно иметь большой объем справочных данных. Но что делать, если нужных данных совсем нет, или не достаточно? Такое состояние называется холодным началом (cold start). Например, на сайте зарегистрировался новый пользователь, и система еще ничего о нем не знает. Или в магазине появился новый товар, который никто никогда не покупал и не оценивал. Или совсем плохо, система только начала свою работу и данных у нее нет вообще. Посмотрим, что можно сделать в таких ситуациях.
Отвлекайте пользователя
Если система рекомендаций — это только одна из возможностей вашего сервиса, то вы можете развлекать пользователя другими функциями, пока система не соберет необходимые ей данные. Необходимое для этого время напрямую зависит от активности пользователя. Вряд ли его можно точно рассчитать, но важно представлять себе, в каких примерно рамках оно лежит.
Для систем, собирающих данные открыто, этот процесс в некоторых случая можно ускорить, дав пользователю возможность активно «дрессировать» систему. Можно частично открыть принципы работы системы и данные, которые она использует, это поможет более шустрым пользователям быстро настроить систему под себя.
Используйте сторонние ресурсы
Некоторую информацию о пользователе можно выловить за пределами вашего сайта. Кое-что можно узнать, проанализировав его историю посещений других сайтов, уделяя особенное внимание поисковым запросам (полезно будет ознакомиться со статьей "Определение пола по истории навигации" как хорошим примером анализа истории). Имея некоторые личные данные о пользователе, например, его email, можно найти информацию о нем в его блоге или социальных сетях. Благо, множество сервисов обеспечивают открытый доступ к информации через API. Полученные в результате данные можно использовать по отдельности, или отнести пользователя к какому-нибудь стереотипу и сделать предположение о других его качествах.
При создании системы подумайте, какие дополнительные источники информации будут для нее доступны, возможно какие-то из них стоит использовать. Эти методы могут быть достаточно трудоемкими и вполне возможно, что данные придется собирать по крупицам, но если для системы важно знать как о пользователе как можно больше и как можно быстрее, то они могут помочь.
Статистика
Следующие два метода дают более объективные результаты. Их суть в том, что мы можем попытаться предсказать отношение пользователя к новому объекту, основываясь на том, как он оценивал другие объекты, и как новый объект оценили другие пользователи.
Для примера возьмем один из алгоритмов коллективной фильтрации — Slope One. Для предсказания рейтинга он использует среднюю разницу между объектом, оценку которого система пытается определить, и объектом, оценку которого она уже знает.
Допустим, у нас есть некоторые данные о том, кто как оценил товар:
| Товар А | Товар Б | Товар В | |
| Саша | 4 | не оценивал | 8 |
| Катя | 6 | 2 | 4 |
| Артур | 5 | 3 | не оценивал |
Зная, какая средняя разница между оценками товара А и Б, мы можем вычислить оценку Саши для товара Б:
Хотя метод достаточно грубый, он работает.
Векторная модель
Второй достаточно простой, но очень элегантный и эффективный метод заключается в том, чтобы представить сравниваемые объекты в виде многомерных векторов, где в качестве координат используется численное представление некоторых его свойств. Тогда величиной, характеризующей сходство этих объектов будет косинус угла между векторами. Обозначим вектора A и B, тогда косинус угла между ними равен (по определению скалярного произведения):
где A*B — скалярное произведение векторов, а |A||B| — произведение их модулей.
Очевидно, что в результате мы получим число от -1 до 1 включительно (от 0 до 1, если оба вектора положительны). Число 1 значит, что вектора направлены одинаково, и объекты идентичны; 0 значит, что вектора ортогональны (перпендикулярны), и объекты не имеют ничего общего; -1 — что вектора направлены в противоположные стороны, и наши объекты тоже противоположны.
В качестве координат вектора можно использовать любые параметры, по которым можно сравнивать два объекта и которые можно представить в численном виде. Например, если нам надо сравнить два текста, то за измерения мы можем принять встречающиеся в них слова, а за координаты — количество их использований в тексте (хотя лучше использовать их релевантность слова к тексту, полученную, например, методом TD-IDF). Более подробно о представлении текстов в виде векторов можно прочитать в статье "Vector space model", а в статье про Slope One есть пример использование вектора с бинарными величинами.
Вернемся к нашему примеру, и попытаемся определить оценку Артура товару В, на основе сходства его мнения с Катей. В виде векторов мы представим Артура и Катю, в качестве измерений используем товары, а координатами послужат их оценки. Тогда:
Очевидно, что для подобной оценки лучше брать посетителей, мнения которых совпадают.
В проекте moismi.ru я использовал этот алгоритм для поиска похожих тегов. Вот несколько наглядных примеров эффективности векторной модели (внимание на облако тегов в правой части сайта): "Microsoft", "браузер", "Google". Несколько хуже он работает для более редких тегов.
Оригинал на моем блоге
23.04.2009 14:37+0400